
Esta situación podría ser verdad, veamos. Un investigador consulta su reloj inteligente tras una jornada intensa. Según el dispositivo, ha estado pedaleando durante tres horas. Sin embargo, no ha tocado una bicicleta. El ritmo cardíaco acelerado que el algoritmo de salud interpretó como ejercicio era, en realidad, el reflejo de una euforia científica: acababa de culminar un avance clave en su investigación. Este pequeño malentendido no solo hace sonreír, sino que también ilustra uno de los mayores retos de la inteligencia artificial (IA): cómo entender con precisión lo que los datos significan realmente.
El protagonista de esa anécdota es Eslam Abdelaleem, físico y autor principal de un estudio publicado en Journal of Machine Learning Research. Junto a Ilya Nemenman y Michael Martini, desarrolló un marco conceptual que ordena los métodos de IA de forma estructurada y comprensible, como si se tratara de una tabla periódica. La propuesta no solo busca mejorar el diseño de algoritmos, sino también facilitar su comprensión, su eficiencia y su aplicabilidad a problemas reales.
La complejidad de la IA y el problema de elegir
A medida que la inteligencia artificial se expande, también lo hacen las opciones disponibles para desarrollarla. Existen cientos de métodos, modelos y funciones de pérdida, cada uno optimizado para tareas y tipos de datos diferentes: imágenes, texto, sonido, video o combinaciones de todos ellos. El problema es que, ante un nuevo desafío, no hay una guía clara sobre qué técnica es la mejor opción.
Según el estudio, “se han ideado cientos de funciones de pérdida diferentes para sistemas de IA multimodal y algunas pueden ser mejores que otras, según el contexto”. La selección adecuada suele requerir un trabajo artesanal, con múltiples pruebas y errores. Este enfoque consume tiempo, datos y recursos computacionales.
Lo que propone el equipo de Emory University es distinto: unificar todos esos caminos dentro de un marco común, que ayude a comprender las relaciones entre los métodos existentes y facilite la creación de nuevos algoritmos ajustados a cada necesidad. Emory resume el logro como “una visión unificada de los métodos de IA” que puede acelerar la innovación.
Un marco como dial de control
El corazón del estudio es un marco llamado DVMIB (Deep Variational Multivariate Information Bottleneck). Esta herramienta matemática permite representar diferentes métodos de IA bajo una misma lógica: comprimir los datos solo lo suficiente para conservar lo esencial. En lugar de tratar cada algoritmo como una fórmula independiente, DVMIB los agrupa según qué tipo de información retienen y cuál descartan.
El equipo lo define como “un marco matemático unificador para derivar funciones de pérdida específicas según el problema, basado en qué información conservar y cuál descartar”. Es decir, proporciona las reglas para construir algoritmos a medida, con criterios claros. Según el coautor Michael Martini, “nuestro marco es esencialmente como un dial de control” que permite ajustar la cantidad de información que se desea mantener para resolver un problema específico.
A diferencia de enfoques que solo se centran en resultados, DVMIB permite entender por qué funciona un modelo, no solo si funciona. Y eso cambia la forma de diseñar sistemas de IA: no como cajas negras, sino como estructuras comprensibles y adaptables.
El papel del cuello de botella en la inteligencia artificial
Uno de los conceptos clave en los métodos analizados en el artículo es el de “cuello de botella”. Aunque suene técnico, su función es clara: se trata de una fase del modelo donde la información se comprime de forma controlada, obligando al sistema a conservar solo lo esencial. Esta estrategia se ha convertido en una herramienta central para extraer representaciones útiles y reducir el ruido en los datos.
En términos técnicos, los cuellos de botella se corresponden con variables intermedias, como Zₓ o Zᵧ, que se encuentran entre los datos de entrada (como X o Y) y la salida reconstruida o predicha. En lugar de dejar que el modelo almacene todos los detalles posibles, se le fuerza a representar la información usando menos dimensiones o menos capacidad. De este modo, la red neuronal se ve obligada a identificar qué patrones o características son verdaderamente importantes.
X Zₓ Y Diagrama de cuello de botella en IA <text x="250" y="160" text-anchor="middle" font-size="Este tipo de estructura es fundamental en muchos de los métodos presentados en la tabla comparativa del paper. Por ejemplo, en el modelo DVIB, se utilizan dos cuellos de botella separados —uno para X y otro para Y— que se entrenan con la ayuda de la vista complementaria. La compresión en Zₓ se entrena a partir de la información de Y, lo que promueve una representación que capta lo que ambos comparten. En el caso de DVSIB, el enfoque es aún más simétrico: se generan dos representaciones comprimidas, una para cada vista, que luego se comparan para identificar relaciones comunes.
La entrada X se comprime en Zₓ (representación latente), que luego se usa para reconstruir Y.
Esta arquitectura no solo mejora la eficiencia del aprendizaje, sino que también permite que los modelos desarrollen una forma de razonamiento más general. Al eliminar detalles innecesarios, el sistema aprende a centrarse en lo que realmente importa para comprender, predecir o generar datos. En contextos donde hay múltiples fuentes de información —como texto e imagen, o imagen y sonido—, el cuello de botella facilita una integración más inteligente y coherente de los datos.
El nacimiento de una tabla periódica de algoritmos
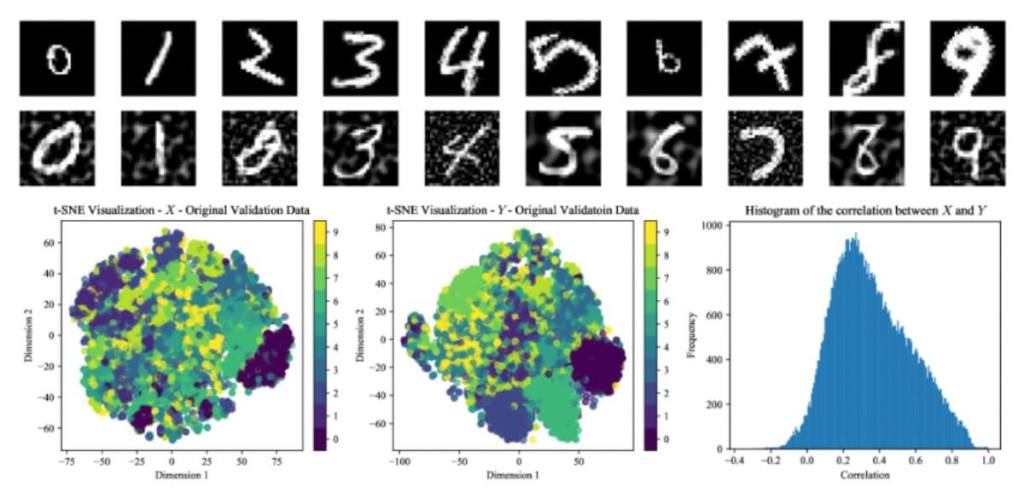
El marco DVMIB no es solo una idea teórica. Los investigadores lo aplicaron a diversos métodos ya existentes, demostrando que pueden derivarse como casos particulares dentro del marco general. Eso incluye técnicas clásicas como el Variational Information Bottleneck o nuevas propuestas como DVSIB (Deep Variational Symmetric Information Bottleneck), una herramienta diseñada por el propio equipo.
DVSIB es capaz de trabajar con dos conjuntos de datos distintos a la vez, comprimiéndolos para conservar solo la información común y útil. En los experimentos realizados, este modelo alcanzó una precisión del 97,8 % en la clasificación de imágenes distorsionadas del conjunto Noisy MNIST, superando otros métodos similares. Además, logró estos resultados usando menos datos y menor potencia de cálculo.
Tal como señala el estudio, “podemos derivar más fácilmente funciones de pérdida, que pueden resolver los problemas que interesan con cantidades menores de datos de entrenamiento”. Esto tiene implicaciones importantes para la sostenibilidad de los sistemas de IA, que muchas veces consumen enormes recursos computacionales.
Una arquitectura para comprimir y reconstruir
Una de las claves visuales para entender cómo funciona el modelo DVSIB es la Figura 1 del estudio, donde se representan los diagramas del codificador y del decodificador. Este esquema, aunque sobrio, resume con precisión cómo el modelo procesa los datos de entrada y los transforma en información útil.
En el lado izquierdo del gráfico aparece el codificador. Las variables X e Y representan dos fuentes distintas de datos, que pueden ser, por ejemplo, imágenes y etiquetas, o texto y audio. A partir de esa entrada, el modelo genera dos nuevas variables: Zₓ y Zᵧ, que son versiones comprimidas de los datos originales. En ese paso, el sistema descarta la información que considera irrelevante y conserva solo lo esencial para realizar la tarea.

A la derecha, el decodificador toma esas variables comprimidas y trata de reconstruir las entradas originales, en este caso, X e Y. Pero lo interesante no es solo la reconstrucción: el modelo también está diseñado para encontrar los elementos comunes entre ambas fuentes de datos. Eso se representa con una flecha que conecta directamente Zₓ con Zᵧ, indicando que existe una relación cruzada en la forma en que el modelo interpreta ambos conjuntos.
Este tipo de estructura resulta especialmente útil en contextos donde los datos provienen de múltiples fuentes y es necesario integrarlos de manera coherente. Además, permite ajustar el modelo según el tipo de problema, gracias al control sobre cuánto se comprime la información. Esta capacidad de adaptación es uno de los pilares del marco DVMIB: un sistema que no solo busca buenos resultados, sino que también explica cómo los consigue.
Hacer ciencia con corazón (y con errores)
El camino hasta llegar a este marco unificador no fue rápido. Abdelaleem y Martini trabajaron durante años, probando ecuaciones en papel, discutiendo ideas en la pizarra y volviendo a empezar cada vez que algo no cuadraba. “Fue mucho ensayo y error, y volver una y otra vez a la pizarra”, recuerda Martini.
Ese esfuerzo culminó en un momento de eureka, cuando comprobaron que su modelo podía identificar automáticamente las características importantes compartidas entre dos conjuntos de datos. El descubrimiento fue tan intenso que el smartwatch de Abdelaleem lo confundió con una sesión de ciclismo de tres horas. “Así interpretó el nivel de emoción que estaba sintiendo”, comentó él mismo, como relató la Universidad de Emory.
Más allá de la anécdota, el episodio refleja cómo este proyecto combina rigor matemático, intuición física y una motivación profundamente humana: entender cómo funcionan las cosas para poder mejorarlas.
Del laboratorio a la biología y la cognición
El equipo espera que su marco sea adoptado por otros investigadores y desarrolladores para diseñar algoritmos adaptados a sus propias preguntas científicas. Esto abre la puerta a nuevas aplicaciones, incluyendo campos donde hoy no es posible trabajar por falta de datos o de modelos adecuados.
Un área especialmente prometedora es la biología y la neurociencia. Según Abdelaleem, uno de sus intereses es “entender cómo tu cerebro comprime y procesa simultáneamente múltiples fuentes de información”. El objetivo sería desarrollar modelos que permitan comparar el funcionamiento del cerebro humano con los sistemas de aprendizaje automático, y así entender mejor ambos.
También se menciona la posibilidad de que el marco contribuya a diseñar sistemas de IA más precisos, eficientes y confiables. En un contexto donde se exige mayor transparencia y sostenibilidad, este tipo de herramientas podría marcar una diferencia decisiva.
Una guía para el futuro de la inteligencia artificial
La inteligencia artificial ha evolucionado hasta convertirse en una pieza clave de la ciencia, la tecnología y la vida cotidiana. Pero su propia complejidad puede convertirse en un obstáculo. El marco propuesto por Abdelaleem, Nemenman y Martini es un intento valiente y riguroso de poner orden en ese universo en expansión, ofreciendo una estructura clara para navegarlo.
Así como la tabla periódica permitió a generaciones de químicos entender las relaciones entre los elementos y predecir nuevas sustancias, esta “tabla de la IA” aspira a guiar la creación de modelos más eficientes, comprensibles y útiles. No solo permite diseñar mejores algoritmos, sino que también ayuda a entender por qué funcionan, algo cada vez más necesario en una era dominada por sistemas opacos.
Referencias
- Thiry, Médard y Milnes, Anthony. 2024. “Reports Engineered ‘landmarks’ associated with Late Paleolithic engraved shelters”. Journal of Archaeological Science: Reports, 55: 1-25. DOI: 10.1016/j.jasrep.2024.104490



